



Huge amounts of video data today exists in consumer and enterprise applications, but interaction with video stored in huge data banks requires better tools to describe, organise and manage that video data. For this reason, private companies and research institutes have joined forces in research projects exploring the possibilities of automatically describing and categorising the content of multimedia and video in particular. Manually describing the content of video is of course very time consuming and automated methods are needed. The goal is to automatically create video abstracts as structured media is more suitable for search and retrieval.
Imagine if all the video on YouTube could be automatically described by a software application. Then the act of searching in the video archive would no longer be a result of the subjective tags each person manually uses to describe the video when it is uploaded. However, these application types are commercially distant.
Large amounts of video are of course also to be found in security installations involving cameras. The interest in VCA has increased during recent years, and will be the focus of this article. Within security, VCA is mainly used to analyse real-time video. However, it can also be used to scan recorded video by setting certain parameters for the software to look for, potentially a very time saving function that further adds value in a VCA-installation.
To shed light on what makes up a typical video installation and why it can not be classified as intelligent or analytic, we use an example of a shopping mall. Basically, a number of cameras are more or less directly connected to a number of displays, which sometimes are watched by operators and perhaps also recorded. Usually, the video processing performed, if any, extends to mere image enhancement for display purposes. Any analysis and comprehension of what is going on in the surveyed areas is on the part of the operators. Fortunately, most of the time nothing special or threatening happens. Unfortunately, research shows that even trained operators lose up to 90 % of their attention within just 22 minutes. In the case of an illegal event of some sort, the video surveillance system itself provides no more support than making available the recorded video footage. If we take into account the previously mentioned operator attention span statistics, the probability that a critical event is stopped or handled thanks to the camera is less than satisfying, at least for the most part. The investigation of what happened prior, during and after the event must be made by manually scanning the recorded video, a potentially cumbersome and time-wasting task. Since no real support is offered by the system, neither in real time or offline, such a system can not be classified as analytic or intelligent.
 |
| Before any analysis takes place, meta-data has to be extracted from the video stream. The meta data contains information such as the speed, size and position of objects |
What is VCA?
In contrast to the shopping mall example, video content analysis is expected to provide a number of automatic functions that simplify and at least to some extent overcome the limitations of the operator, both in real-time and in off-line investigations.
Before going into depth about the technology of video content analysis, a more basic type of video analytics has been available for more than 20 years, namely video motion detection. Motion detection is today an integrated feature of many digital video cameras and video management systems. VMD looks at changes in pixel value (motion) in an image and triggers an event if the change is above a user-defined threshold. More advanced implementations allow the user to trigger events only if the motion appears within a given zone of the image or if the size of the moving area is above a certain limit.
Because the VMD technology is quite simplistic, its use is limited by a large amount of false alarms. With this we mean events triggered even if there is no real object moving in the scene. The most important benefit of VMD is that it is often used to control when video footage is recorded and not, since a static picture seldom is of interest, and for that reason saves storage space.
So, VMD doesn’t appear very intelligent. What is it then that makes a video content analysis system intelligent, and does it make sense at all to call a video analytics system intelligent?
If we return to the shopping mall example again, and now equip it with a video content analysis system we can see a number of improvements:
- Since the shopping mall consists of a number of shops, entrances/exits, open areas and hall ways it is a challenge in the conventional system to get a good overview of the entire mall. However, a VCA-system does "know” the relation between the physical network of entrances/exits, hall ways etc to the network of cameras deployed in the mall. Furthermore, the VCA-system can track the people and objects through this network in a consistent way. In this way the operators see a significantly improved overview of the mall. For example, it becomes possible to ask the VCA-system where a culprit or adversary has come from and, perhaps more importantly, where he can run and where he can be intercepted.
- From time to time it may be necessary to pay special attention to certain areas of the mall. A conventional setup will require that an operator manually watches this area carefully, which will either require him to lower his attention to other areas or will require an additional operator. In a VCA-solution, the operator can define a virtual security area and associated rules to trigger alerts. He can attend his regular duties while the VCA-system monitors the defined areas and alerts only at specified events.
- In the event of a rule breakage, the operator is alerted but also a pan/tilt/zoom capable HDTV camera can automatically be directed towards the location of the event to acquire high quality pictures of the event.
- A VCA-system might also contain modules for biometric identification, for example for the identification of the operators themselves as they enter sensitive areas.
How does VCA work?
VCA is made possible through the creation and analysis of meta-data. Typical examples of meta-data are:
- Object size and position in an image
- Object Speed
- License plate number
In other words, meta-data is data about data, or data describing the contents of an image. Since these data are then put forward for further analysis it is obvious that the nature and the quality of the data are of importance.
First, it is important that only real objects are described so that not vegetation moving in the wind or a shadow on the ground is falsely reported to be a real object.
Secondly, it is important that the meta-data are sufficiently accurate. The obvious example is Automatic Number Plate Recognition (ANPR). If the accuracy of the license plate ID is poor, then the ANPR system is rendered useless. Also, if the size of an object is inaccurately estimated it is a risk that the analysis result is wrong. Let’s say that a system is configured to raise an event if an object above a given size enters the scene. If the object size is inaccurately estimated it is a risk that a person can enter a forbidden area without triggering an alarm. The more advanced meta-data analysis the data is subject to the more important accuracy is.
Third, the nature of the data is important. It is sufficient to know the position of an object in the picture in order to implement a sterile zone or trip wire alarm functionality. However, imagine the possibilities that open up if the objects’ positions are given in a geographical (map) coordinates and the objects are classified as human, car, animal etc.
When it comes to the end user value, the meta-data analysis is of interest. It is the result of this process that is presented to the user as events.
The analysis of a person’s position over time can result in a perimeter breach alert or a loitering alert depending on the movement of the person and the type of analysis that is performed. If the meta-data contains information about the objects’ geographical position, a meta-data analysis can decide if a car is speeding or a person is running. Information about each car’s speed can again be used to calculate average speed on a road or to raise an alert in the event of congestion.
In a high security facility, an organised break-in or attack can be detected earlier if the system is programmed to trigger an alarm if several people are approaching a perimeter at different places at the same time. If a video analytics system is capable of generating meta-data describing each person in a robust way, the person can theoretically be tracked between cameras and his movement through a city or building can be reconstructed.
Background differentiation
 Original VideoFeed. |
When discussing how video content analysis works it is also important to shed light on the separation of objects from the background in a video stream. There are large differences in details when it comes to the implementation of background differentiation technology, especially the methods used to filter out image noise and image disturbances caused by changing lighting conditions and weather effects such as wind, rain and snow. The basic steps of a general background differentiation are described below. |
 Segmentation. |
Segmentation |
 Clustering. |
Clustering |
 Classification. |
Classification |
Another type of approach is to use what is commonly known as template matching techniques. Common for these techniques are that they compare the object to a library of templates and calculating the likelihood that the object is of the similar class as the template. This method can be further developed to extract an object from single images making it unnecessary to perform background differentiation. However, to our knowledge these methods are only tested in research projects and not yet implemented in commercially available video analytics products.
The disadvantages of the direct classification techniques are that they require more computing power and higher resolution (more pixels) across the object. This means that some VCA systems are able to detect and classify objects at long distances (200 m with 640x480 resolution) whereas other systems often stop at 50-75 m due to fundamental technological limitations.
 Tracking – Man Upright. |
The last step in the process is tracking, where the task is to assign a unique ID and keep track of it as long as it is in the cameras field of view. Different techniques exist to track objects that are partly or fully obscured part of the time, and there are large differences in the different systems’ ability to track an object under difficult conditions, e.g. poor image quality. |
Distinction between Features and Functions
So what type of events can be detected? BSIA (British Security Industry Association) puts it this way:
In theory any "behaviour” that can both be seen and accurately defined on a video image can be automatically identified and an alert raised.
OK, so the "behaviour” you are looking for has to be seen. This means that if you can’t see if a person is carrying a gun, you can not detect it using video analytics. It is actually a common misconception that this is possible. It is also often heard that "we don’t know what the military is capable of” as a way of justifying a belief that video analytics can do magic.
A more everyday example is the "left item detection”. This feature is meant to detect potentially dangerous objects, e.g. a bomb left behind at an airport or other places where many people travel. The only problem is that a video camera cannot see what’s behind a litter bin or see objects obscured by people passing by.
This brings us to the distinction between feature and function.
With feature (or more precisely, capability feature) we mean that a system is capable of certain things. Function is a more complex matter as it relates both to how the feature is implemented and to what extent it functions, its usability. A commonly used example is a car’s ability to stop. This is a feature every car must have. However, the braking function is implemented as a pedal, not a push-button in the glove compartment, in order for the function to be usable. Further, a sports car has the ability to stop faster than a family car. There are differences in functions.
If we look at all the features that a collection of VCA vendors claim to have we get a very confusing list:
| • Asset Protector | • Virtual Fence |
| • Loitering | • Wrong Direction Detection |
| • Left Item Detection | • Suspicious Directional Movement |
| • Tracking | • Unusual Crowd Formation Detection |
| • Tailgating | • People Counting |
| • Intelli-Search | • Intrusion Detection |
| • Removed Item Detection | • Crowd & Queue Management |
| • Perimeter Defence | • Tripwire Detection |
| • Traditional Video Motion Detection (VMD) | • Unauthorised Activity Detection |
| • Camera Obstruction | • Running Detection |
| • Slip & Fall Detection |
We should now ask, can the "behaviour” be seen, and can it be accurately described? Let’s take a look at "left item detection” again. We already discussed that this "behaviour” can only be seen if the line of sight to the object is not obscured. In other words, it can be seen, but only sometimes. Is the behaviour possible to accurately be described? How do we define a left item? How long must it be left for, and how far from a person does it need to be? If one person leaves a suitcase close to another person, is the suitcase a "left item”? Can it be accurately described? Yes, sometimes.
So, many VCA vendors claim that their system can detect left items, a "behaviour” that can sometimes be described and sometimes be seen. Let’s be honest, this is a feature with poor function.
What then about the other features listed on page 9? What is "unusual crowd formation” and "suspicious directional movement”? How well do the systems live up to these features?
Working principles of VCA
As previously discussed, an important distinguishing feature of a VCA-system is its ability to generate and analyse meta-data. By meta-data we mean, in this context, data describing the contents of an image or video stream in such a way that a comprehension of the ongoing events becomes possible. For example, if the system is to be able to inform the operator whenever a person is running it needs to extract at least the following data from the video stream (the "analytic part”):
- Extract foreground objects
- Estimate size and other distinguishing properties of the foreground objects
- Estimate speed of each object (observe that in order to do this we need a framework for tracking of objects in subsequent image frames)
This extracted data is the meta-data. In the next step the VCA system analyses the meta-data, rather than the raw video data. In this case the meta-data analysis (the intelligent part) consists of:
- Classifying foreground objects into humans and non-humans
- Somehow "knowing” how to distinguish running from walking, standing still and so on.
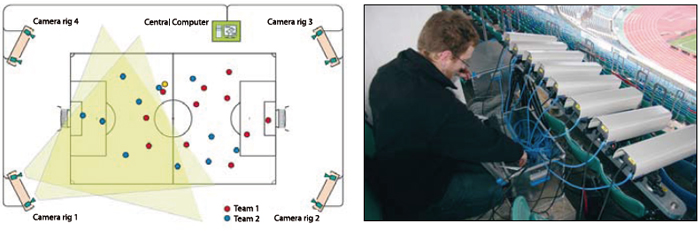
Figure 1. Stereo sensors from Saab are used in the football tracking system from Tracab.
Business possibilities for intelligent video
There are several examples of how businesses can profit by using video analytics in their security installations. Detecting theft and other unwanted behaviour in a supermarket is obvious, but at the same time it could be used to follow up campaigns in the store to see which products are attracting the most customers.
Another example could be an installation of video analytics in a banking environment where the security function would be to prevent theft and fraud but simultaneously could be used to optimise customer queuing by alerting staff of increasing queues.
ROI – important
When procuring a CCTV system today the discussion is all about security, and maybe it should be. There may come a time when business analysts and statistics enter the CCTV scene and claim ROI from security installations. If this time is now, later or never, we do not know. What we do know is that the entire industry should learn and apply the same ideas and fundamental value to any CCTV installation. Return on Investment is a critical tool in sustaining the right to exist in any free economy.
So how do we measure return on investment from a video analytics perspective on a security application? Like any business case we crunch numbers, calculate cost versus efficiency and cost reductions.
Typical applications
A school implementing video analytics surveillance may be looking to lessen vandalism, decrease the cost of security personnel or simply stop having interruptions in their day to day activities. Their ROI could be calculated by investigating the total cost of vandalism in the school compared to the savings a public alarm using intelligent video would give.
In today’s modern society schools are often the target of youth vandalism costing large sums of public funds. The alarm and security installations of today rarely stop any vandalism but merely act as an alarm for security personnel to seek out who may have disturbed the peace within that public facility, often being inno-cent bystanders or kids playing sports on school grounds. With intelligent video each alarm could be filtered to only alert security forces of qualified alarms making sure no false alarms take the time or resources of public personnel.
Another typical area for intelligent video use is with compliance. Today we have a growing number of regulatory bodies setting up rules for different businesses and organisations and many of these rules have a security focus. During manufacturing of biological substances the American FDA sets regulations for security on site even though the factory may reside outside the borders of the United States. FDA regulates for instance how traffic within the compound area may flow and what types of traffic is allowed. Compliance with these rules is usually not an option for any medical company as the US market is far too valuable to even consider surrendering, leaving the manufacturer with complex solutions for measuring speed and direction of vehicles as their only option. In this case a high quality video analytics solution could solve the entire issue in a very cost effective manner making ROI calculations even management consultants would adore.
Calculating ROI
Calculating ROI for video analytics solutions is usually a simple and non complex task; increasing security can often be calculated in a decreased cost of vandalism or theft. But like any good businessman would point out, time is also money, and security personnel definitely require time to investigate false alarms, even though no vandalism or theft occurred. If intelligent video could be used to lessen any false alarm rate, there would definitely exist a business case for making such an installation. A power transformation station is usually an unmanned high security installation somewhere in a populated area with lethal currents running in relatively open areas. Sending security to such an installation is usually costly but necessary since trespassing could lead to fatal injuries. Using video analytics in such a place could lessen false alarm rates making sure only real trespassers would set off alarms and in such a manner save time and money for security forces.
Similar applications exist worldwide at any unmanned installation, like a mobile network base station, or a train traffic tunnel entrance.
Stereo imaging
In conventional surveillance installations usually a single camera covers a particular area, i.e. the video sensors are monocular. In contrast, humans, as well as many other animals, employ binocular vision to watch and understand their surroundings. Monocular vision delivers a 2D projection of a 3D world, i.e. a flat description. Obviously, such a projection limits the kind of information that can be extracted from the scene. For example, any information regarding distance or depth is lost in the projection, making estimation of object size impossible without a terrain model. Binocular or, equivalently, stereo vision does not suffer from this limitation.
However, video sensors can be configured to deliver 3D information as well. Like the eye configuration of humans, this can be achieved by mounting two video sensors together with some in-between distance (say 50 cm) and looking in the same direction.
Saab’s stereo sensor is an example of such a compound imaging sensor which is able to provide stereo imaging in real time. The cameras are set at a small, known, distance from each other and observe the same scene. Signal processing takes the input from the two cameras and creates the depth map of the scene. See figure 1, page 10.
A stereo sensor can be based on almost any video cameras, as long as their camera parameters and their internal distance is known. For surveillance of dynamic scenes it is also important that the cameras are synchronised, the precision of synchronisation needs to be somewhat better than the typical time constant of the moving objects.
The availability of the extra distance (depth) information, as compared to a normal video sensor, is highly useful in a VCA system. For example, this information can be used to accurately measure the actual physical properties of an object as well as easily separate partially occluding objects from each other. Furthermore, this can be achieved without the need of a terrain model. Beside this great advantage, the stereo imaging substantially improves the robustness in the basic processing chain. Since stereo enables an object location in 3D, birds and other distractions can easily be separated out and thereby reduces the false alarm rate. An object can also be easily separated from its cast shadow, which is a challenge in the single camera case. Detection and clustering is also significantly less dependent on varying lighting conditions.
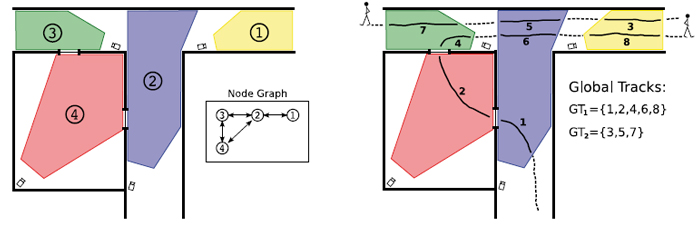
Figure 2. A schematic overview of a camera network and its relation to the geographic network. The inset shows the possible camera to camera transitions. (right) Example of how tracklets from individual cameras might be associated into global tracks through the network of cameras; using the spatio-temporal as well as object appearance.
Consistent tracking
Earlier we briefly discussed the needed for tracking functionality in each individual camera’s field of view. Usually, a normal installation will consist of multiple cameras. Some of these cameras might have overlapping field of views while other pairs might be setup long from each other and have completely different fields of views. For several reasons, a consistent tracking in such a network is a much more challenging problem than tracking in a single field of view:
- The cameras can be widely separated and the object can be out of sight for prolonged times
- The lighting conditions can also be very different making any appearance based object matching a great challenge.
- The cameras themselves can be of different models and their relative setup can vary greatly.
This is a very difficult problem to solve in its entire generality. For example, a brute force attempt would require computations that increase exponentially as the number of cameras and objects increases. However, methods for consistent tracking in networks are evolving to a state where they actually are useful and yield an added value to the end-user. The more successful methods take into consideration how the physical network of entrances/exits, open spaces and hall ways are related to the network of cameras. In this way we only need to associate objects between those fields of view that actually are connected, see Figure 2.
While a consistent tracking in non-overlapping fields of view is still a work in progress, the tracking in overlapping fields of view is nowadays available in commercial systems.
A working network tracking facility can substantially improve the operator’s ability to fulfil the safety and security objectives. First of all, a substantially improved overview of the surveyed area is possible since objects can be traced consistently through the various overlapping and non-overlapping FOVs. Secondly, it becomes possible to assess the earlier whereabouts of the object as well as its future possible routes. Finally, this kind of functionality can be very useful in off-line analysis as well. Since it becomes possible to annotate the recorded video stream with object data, we can efficiently search in the much more condensed meta-data instead of the more cumbersome search in the raw video data.







 Global
Global