



Det finnes mange alternative betegnelser til ”Intelligent video”. Allerede her avsløres det faktum at vi snakker om noe relativt nytt. De alternative benevnelsene som brukes mest er intelligent videoanalyse (IVA) og videoinnholdsanalyse (VCA= Video Content Analysis). I tillegg finnes en mengde ulike variasjoner på disse benevnelsene, men VCA er den benevnelsen som best beskriver hva det er snakk om. Å benevne et teknologisk system som intelligent, i ordets sanne mening, er ikke riktig. Felles for alle de ulike benevnelsene som beskriver VCA er at de har å gjøre med den teknologien som anvendes for å analysere video gjennom beskrivelse av objekters egenskaper og bevegelse.
Skape nytte gjennom forenkling
I dag finnes det store mengder videodata i både forbruker- og bedriftsapplikasjoner, men en effektiv anvendelse krever bedre verktøy for å beskrive, organisere og vedlikeholde videodata. På grunn av dette har selskaper og forskningsmiljøer samarbeidet om å utforske mulighetene for å automatisere prosessen med å beskrive og kategorisere multimedia generelt, og video spesielt. Arbeidet med manuelt å beskrive innholdet i video er selvsagt svært tidskrevende, og derfor trengs automatiserte metoder. Målet er å skape sammendrag automatisk ettersom søk i strukturerte media er en veletablert og svært effektiv teknologi.
Forestill deg at all video på YouTube automatisk kunne beskrives ved hjelp av programvare. Da ville søk etter en spesiell video ikke lenger være et resultat av hvilke subjektive nøkkelord den som har lagt ut videoen har valgt. Slike applikasjoner kommer det til å ta en stund før vi ser kommersielt tilgjengelig.
Videoovervåkning
Store mengder video finnes også i sikkerhetssystemer med kameraovervåkning. Interessen for VCA innenfor sikkerhetsapplikasjoner har økt de siste årene, og er fokuset for denne artikkelen. Innen sikkerhet brukes VCA først og fremst for analyse av video i sann tid, men kan med fordel også benyttes til å søke etter hendelser i innspilt video. Dette er en funksjonalitet som sparer veldig mye tid og dermed bidrar til å øke verdien av en VCA-installasjon.
Uintelligent videoovervåkning
For å gi et eksempel på hva som utgjør et typisk videoovervåkningssystem og hvorfor dette verken kan klassifiseres som intelligent eller analytisk tar vi utgangspunkt i et kjøpesenter. Et antall kamera er mer eller mindre direkte koplet til et antall monitorer. Disse er i noen tilfeller er overvåket av operatører og i noen tilfeller spilles også video inn. I et slikt system skjer det ingen analyse av videostrømmene annet enn eventuelt enkle former for bildeforbedring. All analyse og forståelse av hva som foregår i det overvåkede området er opp til operatørene. Som regel hender det ingenting spesielt eller truende, og det er bra. Studier viser nemlig at en operatør mister opp til 90 % av sin oppmerksomhet etter bare 22 minutter av manuell videoovervåkning. Hvis det da skjer noe som behøver tiltak gir videoovervåkningssystemet ikke annen støtte enn at det går an å se på hendelsesforløpet i ettertid - dersom det spilles inn. Når vi nå vet hvor raskt en operatørs oppmerksomhet svekkes er det ikke vanskelig å forstå at der er stor sannsynlighet for at en hendelse ikke blir oppdaget selv om videoovervåkning er installert. For å undersøke hva som skjedde før, under og etter en hendelse må operatøren se gjennom store mengder innspilt video manuelt. Ettersom systemet ikke gir operatøren noen form for støtte, verken under eller etter en hendelse, kan ikke et slikt system kalles analytisk eller intelligent.
Forskjellen mellom en tradisjonelt videoovervåkningssystem og et system med VCA er at man ved bruk av VCA får automatiske funksjoner som forenkler og til en viss del overkommer svakheten til operatører, både i analyse av video i sann tid og innspilt video.
Bevegelsesdeteksjon
Før vi går nærmere inn på hvordan teknologien bak VCA fungerer skal vi se nærmere på en enklere type videoanalyse som har vært på markedet i mer enn 20 år, nemlig bevegelsesdeteksjon (motion detection). Bevegelsesdeteksjon er i dag integrert i mange digitale overvåkningskamera og programvare. Bevegelsesdeteksjon ser på endringer i pikselverdier (”bevegelse”) i en videostrøm og trigger dersom endringen er over et vist nivå. I mer avanserte system kan det i tillegg stilles krav til at bevegelsen skal skje i et bestemt område av bildet eller at området som endres skal være av en viss størrelse for at det skal trigges alarm eller innspilling skal startes.
Ettersom bevegelsesdeteksjon er en relativt usofistikert teknikk er også anvendelsesområdet begrenset, ikke minst på grunn av at slike system ofte trigger et stort antall falske alarmer. Med falsk alarm mener vi hendelser som trigger alarm/innspilling til tross for at det ikke er virkelige objekter som beveger seg i bildet. Den viktigste foredelen med bevegelsesdeteksjon er at den ofte brukes til å automatisk kontrollere når video spilles inn og ikke ettersom et statisk bilde sjelden er av interesse. Slik sparer bevegelsesdeteksjon mye lagringsplass.
Hva er intelligent?
Så bevegelsesdeteksjon er altså ikke spesielt intelligent. Hva er det da som gjør at VCA betraktes som intelligent? Er det i det hele tatt rimelig å kalle et VCA-system for intelligent?
Hvis vi vender tilbake til kjøpesenteret igjen og nå oppgraderer videoovervåkningssystemet med et tenkt VCA-system så kan vi se et antall forbedringer.
- Ettersom kjøpesenteret består av mange butikker inn- og utganger, åpne områder osv. er det en utfordring for et konvensjonelt system å holde oversikt over hva som foregår. Et VCA-system vet hvor kameraene er plassert i bygningen og hvordan de er plassert i forhold til hverandre. Dessuten kan VCA-systemet følge mennesker og objekter gjennom nettverket slik at operatørene får et forbedret helhetsbilde av hva som foregår. Det blir f. eks. mulig å spørre VCA-systemet hvor en butikk yv kom fra og - kanskje enda viktigere – hvor han tok veien og hvor han kan stanses.
- Av og til kan det bli behov for å spesialovervåke et begrenset område. I et konvensjonelt system betyr det at en operatør må være ekstra oppmerksom på et eller flere kamera. Dette medfører dermed at han minsker sin oppmerksomhet på de øvrige kameraene eller at det er behov for en ekstra operatør. I et VCA-system kan operatøren selv definere et virtuelt sikkerhetsområde med tilhørende regler for å trigge alarm. Han kan altså fortsette å utføre sine normale oppgaver mens VCA-systemet holdet et våkent øye på området som trenger spesiell oppmerksomhet.
- Om en hendelse oppstår som leder til en alarm generert av VCA-systemet vil ikke bare operatøren varsles, men et HDTV kamera med PTZ-funksjon kan automatisk zoome inn på hendelsen og gi nærbilder med høy kvalitet.
- Et VCA-system kan også integreres med biometrisk identifikasjon. Det innebærer at operatørene selv må identifisere seg før de beveger seg inn i et beskyttet område.
 |
| Før analyse må meta-data trekkes ut av videostrømmen. Meta-data inneholder informasjon om f. eks. objekters hastighet, størrelse og posisjon. |
Slik fungerer VCA
VCA foregår i to steg; generering og analyse av meta-data. Typiske eksempler på meta-data er:
- Objekters størrelse og posisjon i bildet.
- Objektets hastighet.
- Bil-kjennetegn.
Meta-data
Viktigheten av at meta-dataene har god nøyaktighet kan belyses ved å se på en applikasjon som nummerskiltgjenkjenning (ANPR). Om ikke et slik system kan skille mellom for eksempel bokstavene U og V kan en fartsbot havne hos feil person. Med andre ord, hvis nøyaktigheten i et ANPR-system er for dårlig blir hele systemet verdiløst. På tilsvarende vis er det ikke bra om størrelsen til et objekt blir feil estimert av et VCA-system slik at f. eks. en person kan bevege seg inn i et forbudt område uten at et VCA-system trigger alarm. Jo høyere sikkerhet som kreves av et VCA-system, jo høyere krav stilles til kvaliteten og nøyaktigheten i meta-dataene. Hvilke type data som leses ut av bildet er også viktig. Er det tilstrekkelig å vite et objekts posisjon i bildet for implementere ’sterile zone’ eller en ’trip wire’-alarm? Tenk hvilke muligheter det kunne gi dersom et objekts posisjon kunne plottes i et kart, og om man kunde klassifisere objektene som mennesker, biler, dyr, osv.
Når det gjelder verdien for sluttbrukeren er det resultatet av meta-data-analysen som er interessant. Det er jo resultatet av den som presenteres som hendelser eller alarmer for brukeren.
En analyse av en persons posisjon over tid kan resultere i overtredelse av en sikkerhetssone avhengig av personens bevegelser og typen av analyse som benyttes. Dersom meta-dataene inneholder informasjon om objektets geografiske posisjon kan en analyse avgjøre om det dreier seg om en bil som kjører for fort eller en person som løper. Informasjon om hver bils fart kan benyttes til å beregne middelhastighet på en veistrekning eller for å detektere og gi alarm ved kødannelse.
I et høysikkerhetsanlegg kan et organisert innbrudd varsles tidligere hvis systemet er konfigurert til å gi alarm dersom et antall personer beveger seg samtidig mot et område. Hvis meta-dataene er av høy kvalitet kan en person, teoretisk sett, følges mellom kamera i en by eller bygning.
 Originalvideo. |
Bakgrunnsdifferensiering |
 Segmentering. |
Segmentering |
 Klynging. |
Klynging |
 Klassifisering – stående person. |
Klassifisering |
En annen gruppe av metoder som benyttes er såkalt ’template matching’. Felles for disse teknikkene er at de sammenligner et objekt med et bibliotek av maler. Deretter beregnes sannsynligheten for at objektet tilhører en bestemt klasse. Denne metoden kan videreutvikles til bare å behøve et enkelt bilde for å detektere et objekt i et bilde til forskjell fra bakgrunnsdifferensiering som behøver en bildestrøm. Men til vår kjennskap har slike metoder bare blitt testet i forskningsprosjekt og er enda ikke kommersielt tilgjengelig i noen VCA-produkt.
Ulempene med direkte klassifiseringsteknikker er at de stiller høyere krav til regnekraft (CPU) og oppløsning (flere piksler). Det betyr at enkelte VCA-system klarer å detektere og klassifisere objekter på lang avstand (200 m med 640x480 oppløsning) mens andre kun 50-70 meter på grunn avteknologiske begrensninger.
 Målfølging – stående person. |
Målfølging |
Skillet mellom ’Features’ og ’Functions’
Så hvilke hendelser kan et VCA-system faktisk detektere? BSIA (British Security Industry Association) uttrykker det slik: Teoretisk sett kan alle hendelser som kan både sees og presist beskrives bli automatisk detektert med VCA.
Altså, hendelser eller oppførsel må kunne sees for å kunne detekteres. Dette betyr at hvis man ikke kan se om en person bærer våpen så kan det heller ikke detekteres av et VCA-system. Det er faktisk en vanlig misforståelse at så er tilfelle. Utsagn som ”vi vet ikke hva militæret kan” brukes ofte som en slags begrunnelse for å tro at videoanalyse kan utføre magi.
Et dagligdags eksempel er det som kalles ’left item detection’ altså deteksjon av gjensatte eller gjenglemte objekter som kofferter. Denne ’feature’ er laget for å detektere potensielt farlige objekter som f. eks. en bombe som er etterlatt på en flyplass eller et annet område der mange mennesker oppholder seg. Problemet er at et videokamera ikke kan se hva som er bak en søppelkasse eller se objekter som stadig dekkes av forbipasserende. Dette bringer oss til forskjellen mellom ’feature’ og funksjon.
Med ‘feature’ (mer persist ‘capability feature’) menes at et system har evnen til å gjøre noe. Funksjon derimot er mer sammensatt ettersom det handler om hvordan ’featuren’ er implementert og i hvilken grad det faktisk fungerer. Et vanlig eksempel er en bils evne til å bremse. Denne ’featuren’ må finnes i alle biler, men selve bremsefunksjonen er implementert i form av en pedal, og ikke en knapp i hanskerommet, for at den skal være anvendbar. Videre, om det dreier seg om en sportsbil stilles det strengere krav til hvor raskt bilen må kunne stoppe enn for en familebil. Det stilles altså ulike krav til funksjon eller funksjonsnivå avhengig av hva bilen skal brukes til og hva den er laget for.
Features
Om vi ser på alle ’features’ som en samling VCA-selskap hevder å ha får vi en forvirrende liste av engelske uttrykk:
| • Asset Protector | • Virtual Fence |
| • Loitering | • Wrong Direction Detection |
| • Left Item Detection | • Suspicious Directional Movement |
| • Tracking | • Unusual Crowd Formation Detection |
| • Tailgating | • People Counting |
| • Intelli-Search | • Intrusion Detection |
| • Removed Item Detection | • Crowd & Queue Management |
| • Perimeter Defence | • Tripwire Detection |
| • Traditional Video Motion Detection (VMD) | • Unauthorised Activity Detection |
| • Camera Obstruction | • Running Detection |
| • Slip & Fall Detection |
Vi kan igjen stille oss spørsmålet hvilke hendelser som faktisk kan sees og om de kan beskrives på en presis måte. Om vi ser på ’left item detection’ har vi tidligere i artikkelen kommet frem til at objektet kan sees dersom det ikke dekkes av noe. Med andre ord kan objektet sees, men bare av og til. Kan så hendelsen beskrives presist? Hvordan definerer vi at et objekt, f. eks. en koffert, er gjensatt? Hvor lenge må objektet stå rolig, og hvor langt unna en person må det være? Om en person setter igjen en koffert i nærheten av en annen person er da kofferten gjensatt? Kan hendelsen beskrives presist? Ja, men bare delvis.
Mange VCA-selskap hevder at deres produkt kan detektere gjensatte objekter, en hendelse som av og til kan sees av et kamera og delvis beskrives presist. La oss være ærlige, dette er en ’feature’ med dårlig funksjonalitet. Hva så med de andre ’features’ i listen ovenfor? Hva er egentlig ’unusual crowd formation detection? Hvor godt kan systemet leve opp til forventningene om en slik "feature”?
Arbeidsprinsipper for VCA
Som tidligere har ulike VCA-system ulik evne til å generere og analysere meta-data. Med meta-data menes i denne sammenheng data som beskriver innholdet i en videostrøm på en slik måte at man kan danne seg en oppfatning av hva som hender i bildet. Hvis systemet for eksempel har evnen til å varsle operatøren når en person løper må det i det minste kunne ekstrahere følgende data fra videostrømmen:
- Skille objekt fra bakgrunn
- Estimere størrelse og andre parametere som beskriver objektet
- Estimere hastigheten til hvert objekt. For å klare dette må systemet kunne følge objekter mellom videobilder.
Slike ekstraherte data er altså meta-data. I neste steg kommer VCA-systemet til å analysere meta-dataene og ikke selve videoen. I dette tilfellet består meta-data-analysen av:
- Klassifisering av forgrunnsobjekter i kategorien ”menneske” og ”ikke-menneske”.
- Analyse av hastigheten til objekter av klasse ”menneske”; tilsvarer hastigheten ”løpe”?
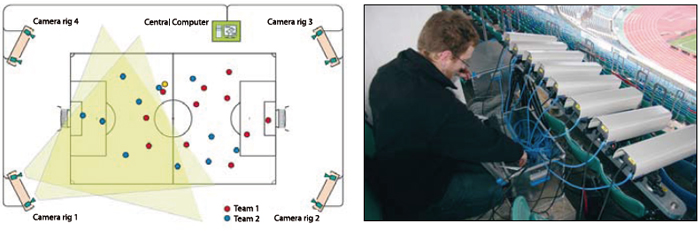
Figur 1: Stereosensorer från Saab används i det tracking-system för fotbollsarenor som Tracab levererar.
Forretningsmuligheter med VCA
Det finnes mange eksempler på hvordan selskaper kan tjene på å benytte VCA i sine sikkerhetssystemer. Fordelen med at et VCA-system kan detektere tyveri og annen uønsket adferd i et kjøpesenter er åpenbar, men VCA-systemet kan også brukes til å følge opp butikkampanjer og til å se hvilke produkter eller reklameplasseringer som trekker flest kunder.
Et annet eksempel kan være å benytte videoanalyse i en bank hvor sikkerhetsfunksjonen består i å forebygge underslag, men samtidig kunne brukes for å optimere håndtering av kø ved å informere personalet om at det trengs flere personer i skranken.
Avkastning på investeringen (ROI)
Når et VCA-system skal anskaffes handler diskusjonene som regel om sikkerhet. Og kanskje skal det være slik, men det kan komme en tid når det også vil stilles krav til avkastning fra sikkerhetsinstallasjoner. Om dette blir nå eller senere vet vi ikke. Det vi vet er at hele sikkerhetsindustrien må lære seg å anvende denne tankegangen også for CCTV-installasjoner. Å beregne en avkastning på en investering er et viktig verktøy i dagens økonomiske virkelighet. Så hvordan måler vi hvilken avkastning en investering i videoanalyse kan ha i en sikkerhetsapplikasjon? Som for alle andre investeringer handler det om å sammenligne kostnadene med investeringens effekt på inntekter eller kostnadsbesparelser.
Typiske applikasjoner
En skole som tar i bruk videoanalyse kan ha til hensikt å redusere hærverk og kostnadene for sikkerhetspersonell. Skolens avkastning på investeringen kan beregnes gjennom å undersøke den totale kostnaden for hærverk og sammenligne denne med besparelsen som kan oppnås ved bruk av VCA.
Hærverk er et stort problem ved mange skoler i dag, og påfører det offentlige store utgifter. Alarm og sikkerhetsinstallasjoner hindrer sjelden hærverk i seg selv, men gir vektere beskjed slik at de skal ta aksjon. Problemet er at alarm kan trigges av at barn og ungdom holder på med lek eller sport. Ved hjelp av VCA kan man i mye større grad filtrere bort uønskede alarm, og på den måten spare kostnader for unødvendige utrykninger.
En annen typisk anvendelse for VCA er oppfyllelse av myndighetspålagte lover og regler. Produsenter av biologisk materiale må for eksempel følge amerikanske FDAs ulike regler for sikring av produksjonslokaler selv om fabrikken befinner seg utenfor USA. FDA bestemmer for eksempel hvor mye og hvilken type trafikk som er akseptabelt innen definerte områder. Om et selskap vil selge til det amerikanske markedet har det ikke annet valg enn å følge gjeldende regler. Dette gjør at mange produsenter mer eller mindre tvinges til å anskaffe system for å måle både hastighet og retning på kjøretøy innenfor fabrikkens område. I slike tilfeller er et egnet VCA-system en kostnadseffektiv løsning. Beregning av avkastning er i slike tilfeller en enkel oppgave.
Å beregne avkastning på en investering
Å beregne avkastning på en VCA-investering er vanligvis ganske enkelt; økt sikkerhet leder ofte til reduserte kostnader for hærverk og tyveri. Men tid er også penger og det går ofte mye tid når vektere skal rykke ut og undersøke årsaken til en alarm som viser seg å være falsk. Hvis VCA kan benyttes til å redusere antallet falske alarmer er det en klar og åpenbar avkastning på investeringen.
En kraftstasjon er normalt en ubemannet og et farlig sted å ferdes på grunn av. åpne strømførende kabler. Kostnaden ved å sende sikkerhetspersonell til et slik sted er høy men nødvendig siden det er livsfarlig å oppholde seg i et slik område for uvedkommende. Ved å benytte videoanalyse i en slik installasjon kan man redusere antallet falske alarmer betydelig ved å bare gi alarm på mennesker som oppholder seg inne på området. Det sparer tid og penger fordi man bare behøver å sende ut sikkerhetspersonell når det virkelig er nødvendig.
Lignende applikasjoner finnes overalt i verden; det være seg basestasjoner for mobilnett eller togtunneler.
Stereoavbildning
I et videoovervåkningssystem dekkes et punkt normalt kun av et kamera om gangen. Videokameraene fungerer altså som ”mono-kamera”. I kontrast til disse vanlige, to-dimensjonale, kamera har menneskers synssystem to øyne for å se og forstå sine omgivelser. Dette gir en oppfatning av virkeligheten i 3D. Et enkelt kamera formidler en 2D-prosjektsjon av en 3D verden, altså en representasjon uten begrep om dybde eller avstand. Det er åpenbart at en slik projektson begrenser hvilken type informasjon som kan ekstraheres fra en videostrøm. Informasjon om avstand og størrelse går tapt i en 2D-prosjektsjon, og dette gjør at beregninger av objekters størrelse ikke er mulig om det ikke finnes en kartmodell over det overvåkede området. Stereosyn har ikke denne begrensningen, og vanlige kamera kan konfigureres i par til å gi et 3D-bilde av virkeligheten. På samme måte som for synssystemet kan dette gjøres ved å sette to videokamera ved siden av hverandre med en viss avstand (f. eks. 50 cm) og rettet i samme retning. Saabs stereosensor er en slik bildesensor som klarer å håndtere stereoavbildning i sann tid. Kameraene settes på en kort, men kjent avstand fra hverandre og er rettet mot samme område. Signalprosessorer analyserer så bilder fra to og to kamera og danner en dybdeforståelse eller kart over området (se figur x side y).
En stereosensor kan bygges med nesten hvilket videokamera som helst, det eneste som kreves er at kameraenes parametere (synsfelt m. fl.) og innbyrdes avstand er kjent. For overvåkning av dynamiske områder er det også viktig at kameraene er synkroniserte. Presisjonen i synkroniseringen må være noe bedre enn den typiske tidskonstanten for objektene i bildet. Det vil si at deteksjon av objekter som beveger seg raskt i bildet stiller strengere krav til synkroniseringen av kameraene enn objekter som beveger seg sakte.
Siden det er mer informasjon (avstand) i et stereobilde enn i et vanlig bilde er stereoteknikk meget anvendbart for VCA-systemer. Informasjon om avstand kan for eksempel brukes til å gjøre nøyaktige målinger at den fysiske størrelsen til et objekt og også skille overlappende objekter fra hverandre. Dette kan i tillegg gjøres uten et terrengkart over området. I tillegg til dette øker stereoavbildning kvaliteten i den grunnleggende prosesskjeden. Ettersom stereoteknikken gir et 3D-bilde av virkeligheten kan fugler og andre forstyrrelser enkelt filtreres vekk, og dermed reduseres antallet falske alarmer. Et objekt kan også lett skilles fra sin skygge, noe som er svært vanskelig med et enkelt kamera. Segmentering og klynging av piksler blir også mye mindre følsomt for endringer i lysforhold.
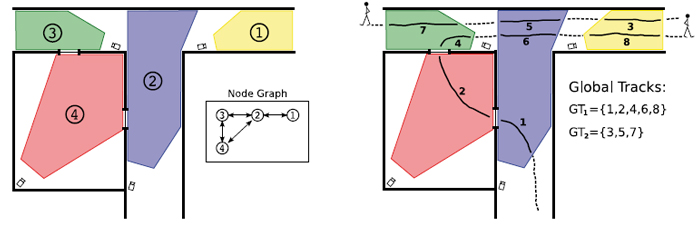
Figur 2: En skjematisk oversikt over et kameranettverk og dets relasjon til det geografiske nettverket. Figuren viser mulige
kamera-til-kamera overganger. (høyre) Et eksempel på hvordan bevegelsesspor fra individuelle kamera kan kobles sammen for å
skape et sammenhengende spor gjennom et kameranettverk.
Konsekvent sporing gjennom kamera
Vi beskrev tidligere i artikkelen behovet for å kunne følge et objekt i et kamerabilde. En typisk videoinstallasjon består av et antall kamera der enkelte kamera har overlappende synsfelt mens andre kamera ikke har det. Det er åpenbart at det er mye vanskeligere å følge objekter som beveger seg mellom kamera enn å følge objekter innen samme kamerabilde.
- Kameraene kan være langt fra hverandre og objektet kan være utenfor kameradekning i lengre perioder.
- Lysforholdene kan variere kraftig, og dette gjør det vanskelig å gjenkjenne et objekt i et annet kamera.
- Kameraene kan være av ulik modell og fabrikat og dermed ha ulik bildekvalitet.
Det er med andre ord et problem som er vanskelig å løse. Om man bare skulle benytte rå datakraft ville behovet for regnekraft øke eksponentielt med antallet kamera. I dag utvikles imidlertid metoder for å følge objekter mellom kamera som snart nærmer seg praktisk anvendelse. De beste av disse metodene tar med i betraktning hvordan kameraenes plassering er relatert til det fysiske nettverket av innganger, utganger og åpne arealer. Dermed trengs det bare å koble objekt mellom synsfelt som er forbundet (se figur 2).
Mange fordeler
Et fungerende nettverk av kamera hvor man automatisk kan følge en person eller objekt fra kamera til kamera kan gjøre en sikkerhetsoperatørs jobb betydelig enklere. Først og fremst skaper dette en bedre oversikt over det overvåkede området. Dessuten blir det mulig å se hvor et objekt har vært før det fanget operatørens oppmerksomhet eller trigget en alarm. Sist, men ikke minst gjør denne funksjonen det lettere å analysere innspilt materiale fordi det blir mulig å koble innspilt video med objektdata. Ettersom meta-data er mye mer strukturert og komprimert sammenlignet med video blir det enklere å søke i det lagrede materialet.






























 Global
Global